!!! abstract 经历了一年的发展,国产 AI 已经慢慢地走向成熟,今天和大家一起看一下人如何把国内的明星产品 智谱AI 和 LlamaIndex 这个数据框架结合起来,处理日常任务。 !!!
国产 AI 产品
大家都知道,今天一整年 AI 和 大模型圈子都是火热非常,几年 8 月份,随着《生成式人工智能服务管理暂行办法》的正式实施, 也为中国自己的生成式人工智能之路,从政策上给出了要求和肯定,让 AIGC 行业发展不再迷茫。
十一月份的时候,我觉得国产AI已经具备了产业应用场景落地的基本条件(主要是指B端), 想要把人工智能和自己公司的产品结合起来需求的同学们可以动起来了。 不过最近工作原因关注国内商业/企业应用较少,各种会议也没关注关注,实在不知道我们 B 端玩家们是否正在撸起袖子热火朝天的干活。 今天就从我自己入手,抛弃 OpenAI,使用我们国内的 AI 平台,展示一下如何使用 LlamaIndex 框架和智谱 AI 结合起来处理常见的应用场景。
国内有哪些大模型
不论开源闭源,我这里随便列几个常见的大模型(排名不分先后):
| 机构/公司 | 模型名称 |
|---|---|
| 百度 | 文心大模型 |
| 抖音 | 云雀大模型 |
| 智谱 | GLM大模型 |
| 中国科学院 | 紫东太初大模型 |
| 百川智能 | 百川大模型 |
| 商汤 | 日日新大模型 |
| MiniMax | ABAB大模型 |
| 上海人工智能实验室 | 书生通用大模型 |
| 科大讯飞 | 星火认知大模型 |
| 腾讯 | 混元大模型 |
| 阿里巴巴 | 通义千问大模型 |
有哪些产品
同样的我们国内看看有哪些类似 ChatGPT 一样的生成式人工智能产品呢?
| 百度 | 文心一言 |
|---|---|
| 抖音 | 豆包 |
| 科大讯飞 | 讯飞星火 |
| 百川智能 | 百川大模型 |
| 智谱 AI | 智谱清言 |
| 阿里巴巴 | 通义千问 |
当然上面的列表不是很全,只是一些我比较熟悉的。
大模型选择和使用
国内大模型或平台的选择大家可以根据自己的需求来,毕竟上面无论那一家都是有非常强大的实力, 且发展迅速。
这些 AI 厂商一般有三种提供服务的方式:
- 模型私有部署:直接部署开源或者闭源的模型(需要显卡);
- AI开发平台:很多平台提供了 LLM 服务,可以在线进行模型测试、开发、部署、微调等服务(直接付费即可);
- API调用:这个就和 OpenAI 早期的服务模式一样,提供 API 的调用。
本文为了方便起见我们直接使用 API 的方式,选择 智谱 AI 作为这次的代表。
!!! note 为什么是智谱 AI 并不是说 智谱AI 一定比其他的大模型好(虽然有不少粉丝这样觉得)。 选择智谱AI 的主要原因还是因为我比较熟悉, 从最初开源 ChatGLM 到 VisualGLM,以及后来 ChatGLM2 和 ChatGLM3,我都有关注。 正好智谱AI 也开放了 API 调用。 !!!
智谱 AI
智谱 AI 由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。 大家可以自行去其官网了解:

当然我们今天的主角是他的开放平台:
注册之后登录进入控制台就可以看到模型、文档、账单等模块:
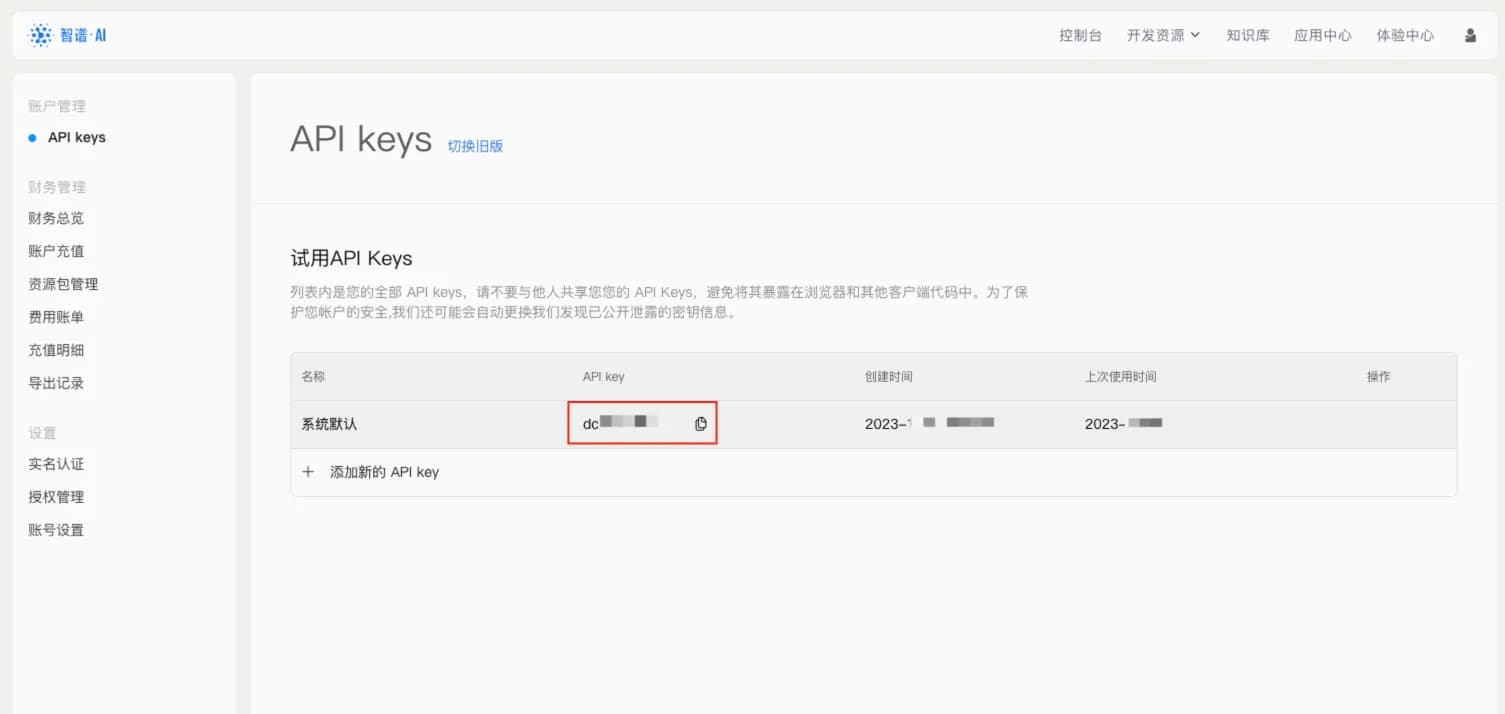
查看 API Key 可以看到默认的 API Key,直接拷贝使用,或者创建新的 API Key:
API 使用
从控制台的首页点击 API 文档,进入 API 的使用指南:
快速安装:
pip install zhipuai然后写一个例子测试下:
import zhipuai
zhipuai.api_key = "xxx" # 你的 api key
def invoke_prompt(prompt):
response = zhipuai.model_api.invoke(
model="chatglm_turbo",
prompt=[
{"role": "user", "content": prompt},
],
top_p=0.7,
temperature=0.9,
)
if response['code'] == 200:
return response['data']['choices'][0]['content']
return 'LLM not worked'
if __name__ == '__main__':
response = invoke_prompt('简单介绍下人工智能是什么')
print(response)回答如下:
人工智能(Artificial Intelligence,简称AI)是一门研究、开发模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的新兴技术科学。 人工智能领域的研究涵盖了多个方面,如机器人、语言识别、图像识别、自然语言处理和专家系统等。其目标是使计算机能够模拟和实现人类智能的功能, 从而在某些领域达到甚至超过人类的智能水平。\n\n人工智能专业是一门多学科交叉的新兴学科,旨在培养掌握人工智能基础理论、 基本方法和应用技术的人才。专业课程包括人工智能概论、认知科学、机器学习、模式识别、深度学习、知识工程、数据挖掘、 物联网等系列课程。\n\n人工智能的发展包括多个阶段,如启蒙、繁荣、低谷等。从20世纪50年代开始,人工智能逐渐成为一门独立的学科。 随着计算机技术、网络技术和大数据技术的快速发展,人工智能进入了一个新的黄金时期。 在我国,人工智能专业的发展也得到了政府和企业的大力支持,被视为未来科技创新的重要驱动力。”
智谱 AI 的提示参数
上面代码我们注意到,prompt 参数是一个数组,其设计是天然针对对话、以及少样本提示的。
比如:
prompt = [
{"role": "user", "content": '提问1'},
{"role": "assistant", "content": '回答1'},
{"role": "user", "content": '提问2'},
{"role": "assistant", "content": '回答2'},
{"role": "user", "content": prompt},
]AI 会跟去前面的对话历史,对最后的 prompt 进行回答。
!!! explain 少样本提示 少样本提示 虽然是提示工程中最简单的一个技术,但这种方法其实有很大的威力, 在一个优秀的 LLM 之上进行少样本提示甚至可以在很多场景下代替模型微调, 达到意想不到的效果。 !!!
好了,现在基本调用是可以了。我们再来实现一个 AI 的常用场景,知识库检索。
Llama Index
我们这次实现知识库,已然使用 LlamaIndex, LlamaIndex 是一个简单灵活且强大的数据框架,用于将自定义数据源连接到大型语言模型。 感兴趣的朋友可以去查看 LlmaIndex 文档 或者去我 LlamaIndex 的合集去了解更多信息。

安装
先用 Pip 简单安装一下 Llama Index:
pip install llama-index然后我们导入下测试是否安装成功:
import llama_index
print(llama_index.__version__)
# 0.9.10接下来让 Llama Index 使用 智谱AI 作为大模型。
支持的 LLM
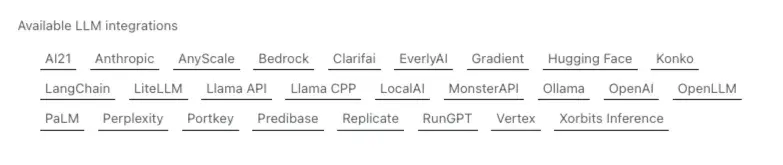
我们到 LlamaIndex 的文档「Available LLM integrations」看下它现在支持哪些大模型。
我们看到,虽然他支持了很多的商业模型和开源项目,但是并没有 「智谱 AI」 以及国内的一众 AI 产品。
国产AI 崛起之路还真是任重而道远啊。
前面我们提到,Llama Index 是一个简单灵活的数据框架,既然官方还没有集成,我们就自己集成一下好了。
集成智谱AI
LlamaIndex 提供了一个叫做 CustomLLM 的抽象类来让我们方便的集成自己的大模型产品:
class CustomLLM(LLM):
"""Simple abstract base class for custom LLMs.
Subclasses must implement the `__init__`, `complete`,
`stream_complete`, and `metadata` methods.
"""从注释就能看到,实现一个自己的 LLM 其实很简单,只需要实现 __init__, complete,
stream_complete 以及 metadata 这几个方法即可。
metadata 方法
!!! explain 什么是元数据 元数据稍微正式的解释是描述数据的数据。比较绕口,需要仔细体会。 简单说就是记录的属性、表的结构、界面的布局、数据的特征、程序的参数。 !!!
上面四个方法中我们比较陌生的应该是 metadata 了,metadata 翻译一下就是元数据,
而 LLM 的元数据是什么, 比较通用的有如下一些:
model_name: str = "chatglm_turbo"top_p = 0.7temperature = 0.9num_output: int = 256context_window: int = 3900
像「模型名称」、「温度」、「top p」这些参数\属性大家想必已经很了解了, 我们简单实现一下:
class ZhipuLLM(CustomLLM):
model_name: str = "chatglm_turbo"
top_p = 0.7
temperature = 0.9
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
context_window=self.context_window,
num_output=self.num_output,
model_name=self.model_name,
)因为 智谱AI 的API 也没有太多的参数,我们把 top_p 和 temperature 取一个比较合理的值,
直接放到调用程序里面,其实可以不需要设计 Metadata,实现一个空方法即可:
class ZhipuLLM(CustomLLM):
@property
def metadata(self) -> LLMMetadata:
return LLMMetadata()complete 方法
接下来就是实现 complete 方法,前面我们有一个 invoke_prompt 方法来实现 智谱AI 的调用,这里直接拿来用,
也不去实例化或者过多设置参数,越简单越好:
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
response = invoke_prompt(prompt)
return CompletionResponse(text=response)!!! note stream_complete 流式返回官方也有例子,我这里就不实现了。 !!!
文本嵌入 Embedding
智谱 AI 也提供了文本嵌入接口,那我们当然也是直接拿来用了,这样子就彻底摆脱了了 OpenAI 和自己搭建模型了。
LlamaIndex 的嵌入式基于 BaseEmbedding 实现的,我们也写一个 智谱AI 的实现,来不及做过多解释了,直接看代码:
class ZhipuEmbedding(BaseEmbedding):
_model: str = PrivateAttr()
_instruction: str = PrivateAttr()
def __init__(
self,
instructor_model_name: str = "text_embedding",
instruction: str = "Represent a document for semantic search:",
**kwargs: Any,
) -> None:
self._model = 'text_embedding'
self._instruction = instruction
super().__init__(**kwargs)
@classmethod
def class_name(cls) -> str:
return "zhipu_embeddings"
async def _aget_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _aget_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = invoke_embedding(query)
return embeddings
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = invoke_embedding(text)
return embeddings
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
return [self._get_text_embedding(text) for text in texts]LlamaIndex 结合 智谱 AI
现在让我们把前面的成果合在一起,写一个简单的程序看看,能不能行得通:
首先我们再目录下放置一个文本文件,当前 PDF、Excel、Docx 都行,我这里还是用之前亚运会奖牌设计的文案:

然后直接运行程序:
# define our LLM
llm = ZhipuLLM()
embed_model = ZhipuEmbedding()
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model
)
# Load the your data
documents = SimpleDirectoryReader(doc_path).load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
# Query and print response
query_engine = index.as_query_engine()
response = query_engine.query("杭州亚运会奖牌的工艺和设计理念?,请用中文回答。")
print(response)来看下回答:
杭州亚运会奖牌的工艺和设计理念如下:
1. 工艺:奖牌采用了一系列复杂的工艺,包括压印成型、
数铣外形及槽坑、修整刷拋、镀金镀银、表面防护等。
绶带采用织锦提花工艺、环保印花技术,双面手工缝合。
此外,奖牌正面采用了江南传统工艺——打鏨雕,
将四种书法(真、草、隶、篆)的杭州与亚奥理事会
的英文缩写有机结合。
2. 设计理念:奖牌设计融合了杭州三大世界文化遗产
——西湖、大运河、良渚古城遗址,
展现了杭州山水景观和江南文化。
奖牌正面勾勒出“三面云山一面城”的杭城画卷,
背面形似方形印章,寓意运动员在杭州亚运会上
留下美好印记。整体设计别具一格,
具有高度辨识度,体现了美美与共、和而不同的含义。
此外,奖牌设计还展现了杭州生态文明之都的气质,
湖光山色,绿水青山,铸就了金山银山,
也体现了勇攀高峰的体育精神。
奖牌直径70毫米,厚度6毫米,
正面圆形渐变色,背面采用杭州江南丝绣技艺呈现的篆刻图案。
整体奖牌设计充满东方意蕴之美,
将深厚底蕴的南宋文化与杭州地域特色相结合,
表达独特的美学理念。回答均来源于文案,但是进行了重新组织,我只想说中文表达如此流畅!远胜我自己。
结语
Llama Index 里使用大模型的地方主要是上面两处。这两个点对接之后,余下的各种玩法也均和使用 OpenAI 无异。 更多的场景以及可落地的 AI 玩法,后面再和大家分享。